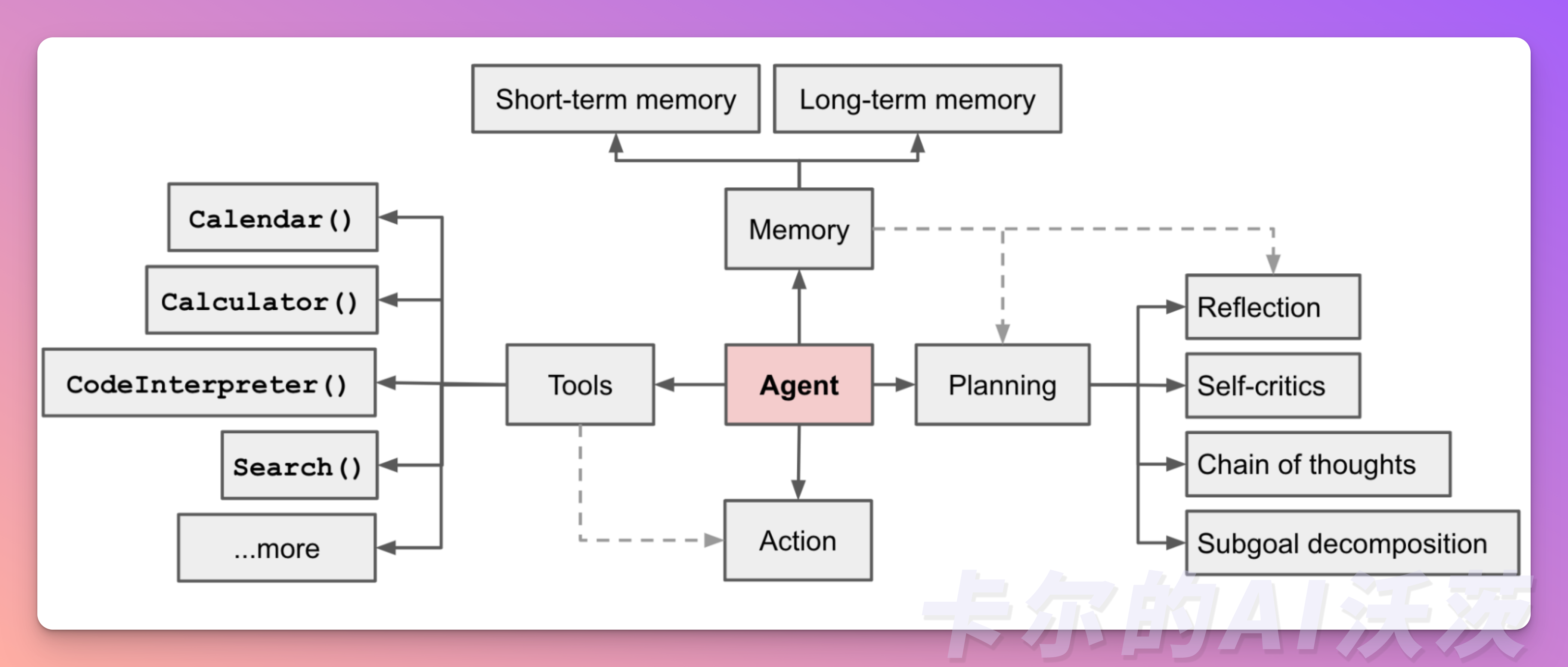
🟢 Agents 组件详解
在以LLM驱动的Agent系统中,LLM扮演着Agent的大脑角色,并辅以几个关键组件:
- 规划:LLM能够进行全面的规划,不仅仅是简单的任务拆分。它可以评估不同的路径和策略,制定最佳的行动计划,以实现用户给出的目标。
- 记忆:LLM具有记忆功能,它可以存储和检索过去的信息和经验。这使得它能够在处理用户查询时,利用之前学到的知识和经验,提供更准确和个性化的答案。
- 工具使用:LLM熟练掌握各种工具和资源,能够灵活运用它们来支持任务的完成。它可以利用搜索引擎、数据库、API等工具,获取和整理相关信息,以满足用户的需求。
🎉开始阅读前,如果你对其他文章感兴趣,可以到欢迎页关注我们!「AI集训营」开源中文社区实时获得后续的更新和最新的教程🎉
组件一:规划
- 子目标和分解:Agent将大型任务分解为可管理的子目标,从而有效地处理复杂的任务。
- 反思和改进:Agent对过去的行动进行自我批评和反思,从错误中学习并改进未来的步骤,从而提高最终结果的质量
处理复杂任务时,往往需要进行多个步骤。为了更好地组织和计划,Agent 需要明确任务的具体内容并开始提前计划。
任务分解
- 思维链(CoT,Chain of thought)已成为一种标准prompting技术,用于增强复杂任务上的模型性能。指示模型 think step by step 将困难任务分解为更小,更简单的步骤。CoT将关注点放在了模型思考过程的可解释性上,使得处理困难任务变得更加可管理。
- 思维树(Tree of Thoughts)通过探索每个步骤的多种推理可能性来扩展CoT。它首先将任务分解为多个思考步骤,并为每个步骤生成多个想法,从而可以创建一个树形结构。形成了一个树形结构。您可以使用广度优先搜索或深度优先搜索来搜索思维树,并根据分类器或多数投票确定每个状态。
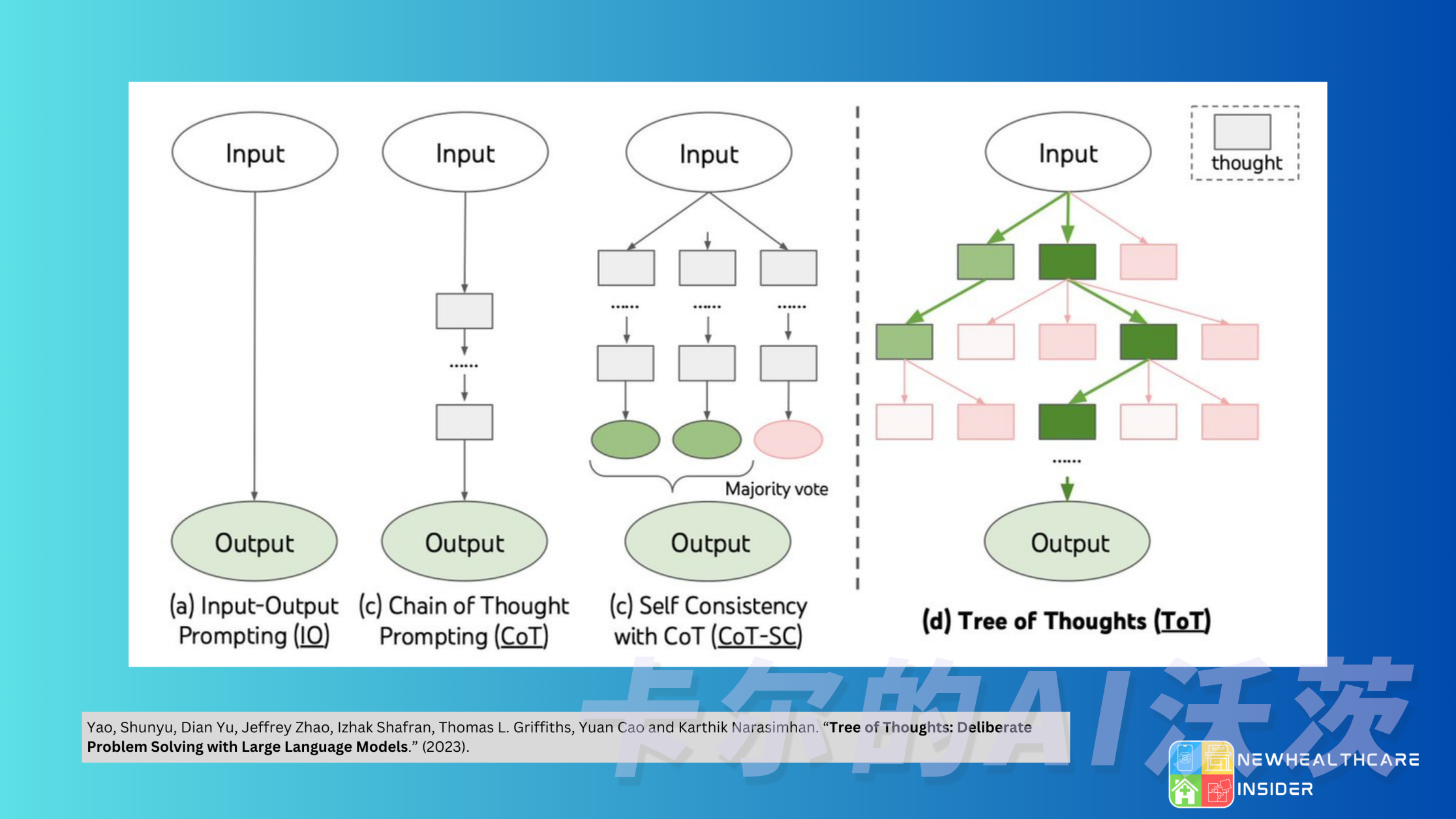
通过以上方法,您可以以三种方式拆解任务:
- 使用简单的提示,引导 LLM 进行拆解,例如:“实现A的步骤”,“实现A的子目标是什么?”。
- 使用特定任务的指令,例如“写一个故事大纲。”用于撰写小说。
- 您可以自己进行任务拆解和规划。如编写脚本要先进行信息提取,再进行内容生成。
反思
在实际任务中,试错是不可避免的,而自我反思在这个过程中起着至关重要的作用。它允许 Agent 通过改进过去的行动决策和纠正以前的错误来进行迭代改进。
反思是 Agent 对事情进行更高层次、更抽象思考的结果。反思是周期性生成的,当Agent感知到的最新事件的重要性评分之和超过一定阈值时,就会生成反思。这可以类比为我们常用的成语“三思而后行”,做重大决策的时候,我们会反思自己先前的决策。
ReAct
ReAct是一种将推理和行动融合在一起的技术,通过将行动空间扩展为特定任务的离散行动和语言空间的组合,将其整合到LLM中。简单来说,特定任务的离散行动使 LLM 能够与环境交互(例如使用维基百科搜索API),语言空间能够促使LLM 生成自然语言的推理轨迹。
ReAct提示模板包括LLM思考的明确步骤,大致格式为:
Thought: ...
Action: ...
Observation: ...
... (Repeated many times)
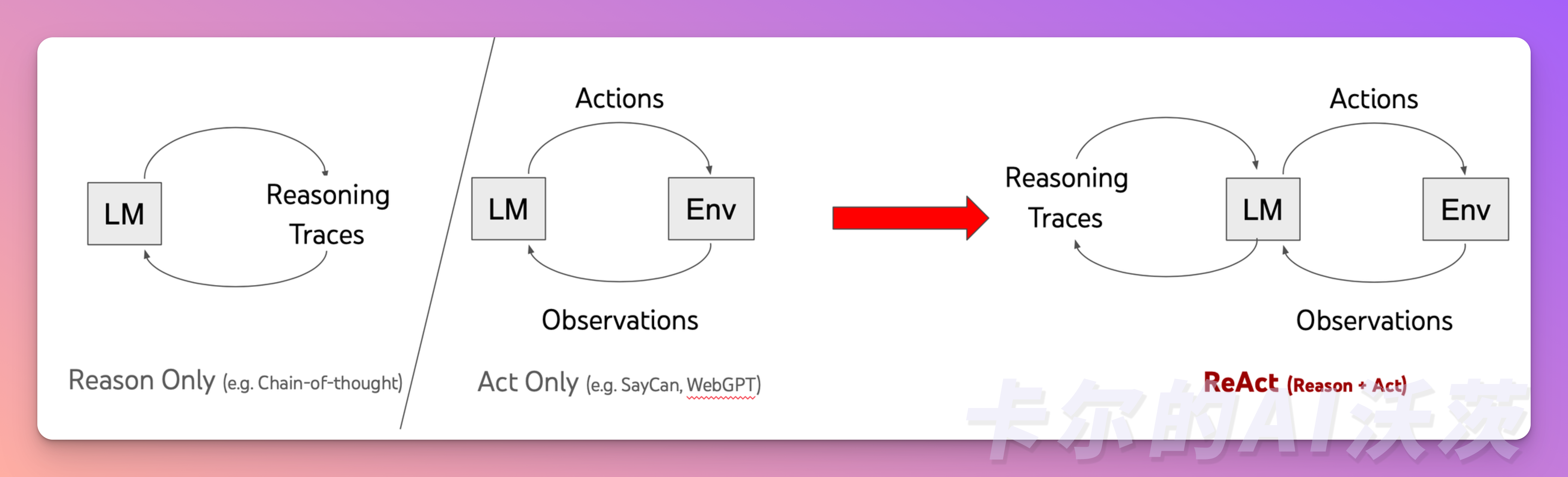
ReAct与CoT的不同之处:CoT 只是在prompt加入了静态的 “Let’s think step by step”;ReAct 的prompt是动态变化
Reflexion
Reflexion是一个框架,为Agent提供动态记忆和自我反思的能力以提高推理技能。Reflexion采用标准的强化学习设置,奖励模型提供简单的二元奖励(即判断行动正确与否),而行动空间遵循 ReAct 中的设置,通过语言加强特定任务的行动空间,增加了复杂的推理步骤。在每个行动之后,Agent会计算一个启发式值,并根据自我反思的结果决定是否重置环境以开始新的试验。
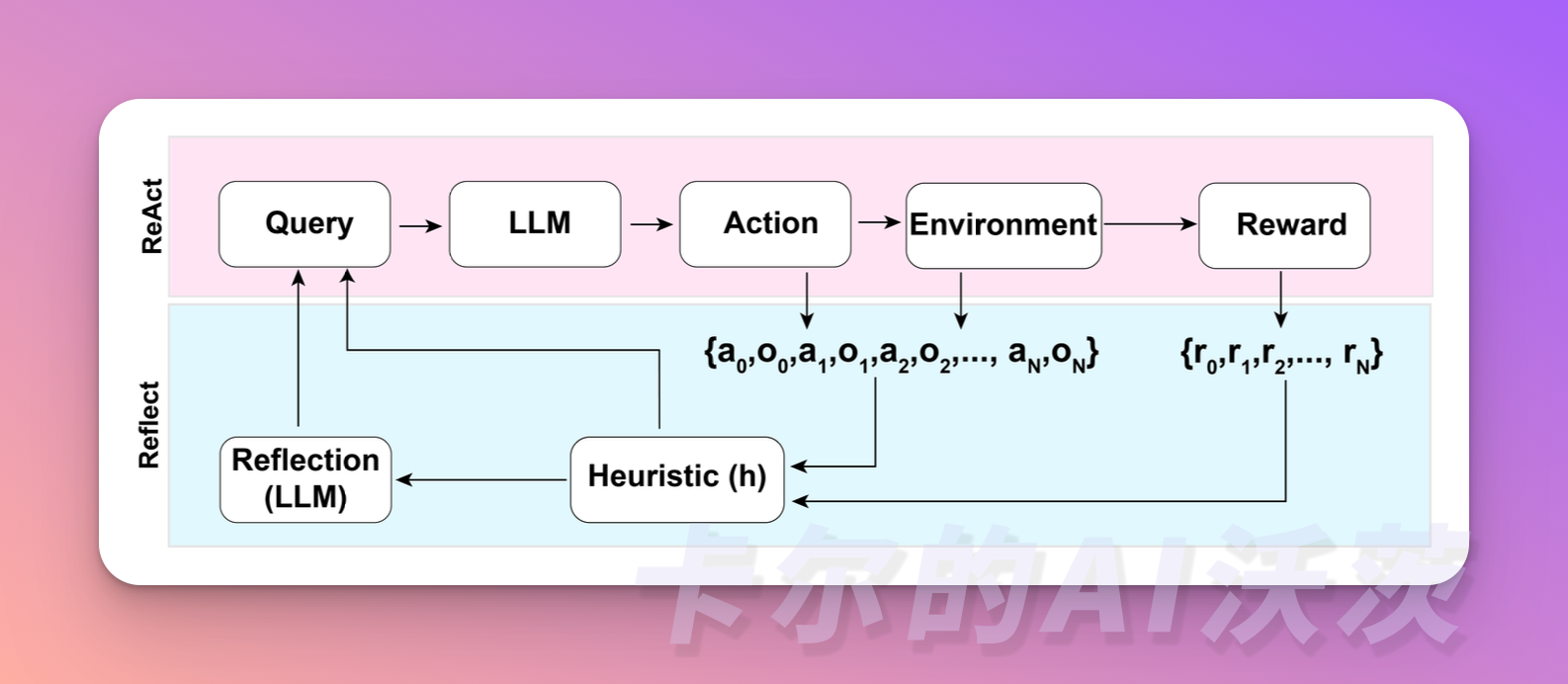
启发式函数用于判断 LLM 的行动轨迹什么时候开始低效或者包含幻觉,并在这个时刻停止任务。低效是指花费了大量时间但没有没有成功的路径。幻觉定义为 LLM 遇到了一系列连续的相同动作,这些动作导致LM在环境中观察到了相同的结果。
请注意这里跟我们一般说的大模型的幻觉不同。大模型的幻觉是指模型会输出一系列看似符合逻辑,但实际错误或并不存在的虚假事实。
组件二:记忆
- 我们可以将上下文学习(context)看成是利用模型的短期记忆(也就是模型能接受输入的最大长度)来学习
- 长期记忆为 Agent 提供了长期存储和召回信息的能力,通常利用外部向量储存和快速检索来实现。
记忆是指获取、储存、保留和后续检索信息的过程。人脑中有多种记忆类型:
- 感觉记忆(Sensory Memory):这是记忆的最早阶段,提供在原始刺激结束后保留感官信息(视觉、听觉等)的印象的能力。感觉记忆通常只持续几秒钟。
- 短期记忆(Short-Term Memory, STM)或工作记忆(Working Memory):它储存我们当前意识到的信息,用于进行复杂的认知任务,比如学习和推理。短期记忆容量通常为7个项目左右,持续时间为20-30秒。
- 长期记忆(Long-Term Memory, LTM):长期记忆可以储存信息很长一段时间,从几天到几十年,其储存容量基本上是无限的。长期记忆有两个子类型:
- 显性 / 陈述记忆(Explicit / declarative memory):指可被有意识回忆的事实和事件的记忆,包括情景记忆(经历和经验)和语义记忆(事实和概念)。
- 隐性 / 程序记忆(Implicit / procedural memory):这种记忆是无意识的,涉及自动执行的技能和例行程序,比如骑自行车或打字。

对于 Agent 来说:
- 感觉记忆作为原始输入,可以是文本、图像或者其他模态的输入。
- 短期记忆则用于上下文学习。它是短暂和有限的,因为它受到Transformer有限上下文窗口长度的限制。
- 长期记忆则是 Agent 可以在查询和关注的外部向量存储,通过快速检索来访问。
记忆流与检索
记忆流(Memory Stream)记录了Agent的全部经历。它是一个内存对象列表,每个对象包含自然语言描述、创建时间戳和最近访问时间戳。记忆流的基本元素是观察(Observation),这是Agent直接感知的事件。观察可以是Agent自身执行的行为,也可以是Agent感知到其他Agent或非Agent对象执行的行为。每个Agent都有自己独立的记忆流。
检索功能根据Agent的当前情况,从记忆流中检索一部分记忆,供语言模型使用。排序打分包括三个方面:
- 近期性(Recency):最近访问的记忆对象得到更高的分数,因此刚刚发生的事件或今天早上的事件可能会更受Agent关注。近期性使用指数衰减函数来衡量,衰减因子为0.99,衰减的基准是上次检索记忆以来的时间。
- 重要性(Importance):根据Agent认为的重要程度,为记忆对象分配不同的分数,区分普通记忆和核心记忆。例如,平凡的事件(比如吃早餐)得到低重要性分数,而与重要的人开会这事件得到高分。重要性分数可以使用不同的实现方式,类似的解决方案就是使用了这个具体的评分模型来输出一个整数分数。
- 相关性(Relevance)为与当前情况相关的记忆对象分配更高的分数。使用常见的向量检索引擎来实现相关性评估。
组件三:使用工具
Agent可以通过学习调用外部API来获取模型权重中所缺少的额外信息,这些信息包括当前信息、代码执行能力和访问专有信息源等。这对于预训练后难以修改的模型权重来说是非常重要的。
掌握使用工具是人类最独特和重要的特质之一。我们通过创造、修改和利用外部工具来突破我们身体和认知的限制。同样地,我们也可以为语言模型(LLM)提供外部工具来显著提升其能力。
MRKL(模块化推理、知识和语言)是一种为自主Agent设计的神经符号架构。MRKL系统包含一组“专家”模块,而LLM 将查询发送到它认为最适合的专家模块。这些模块可以是神经模块(如深度学习模型)或符号模块(如数学计算器、货币转换器、天气API)。
TALM(工具增强语言模型)和Toolformer通过微调语言模型来学习使用外部工具的API。这些数据集是根据增加外部API调用注释是否能够提高模型输出质量而创建的。工具API的集合可以由其他开发人员提供(如插件案例),也可以自定义(如函数调用案例)。
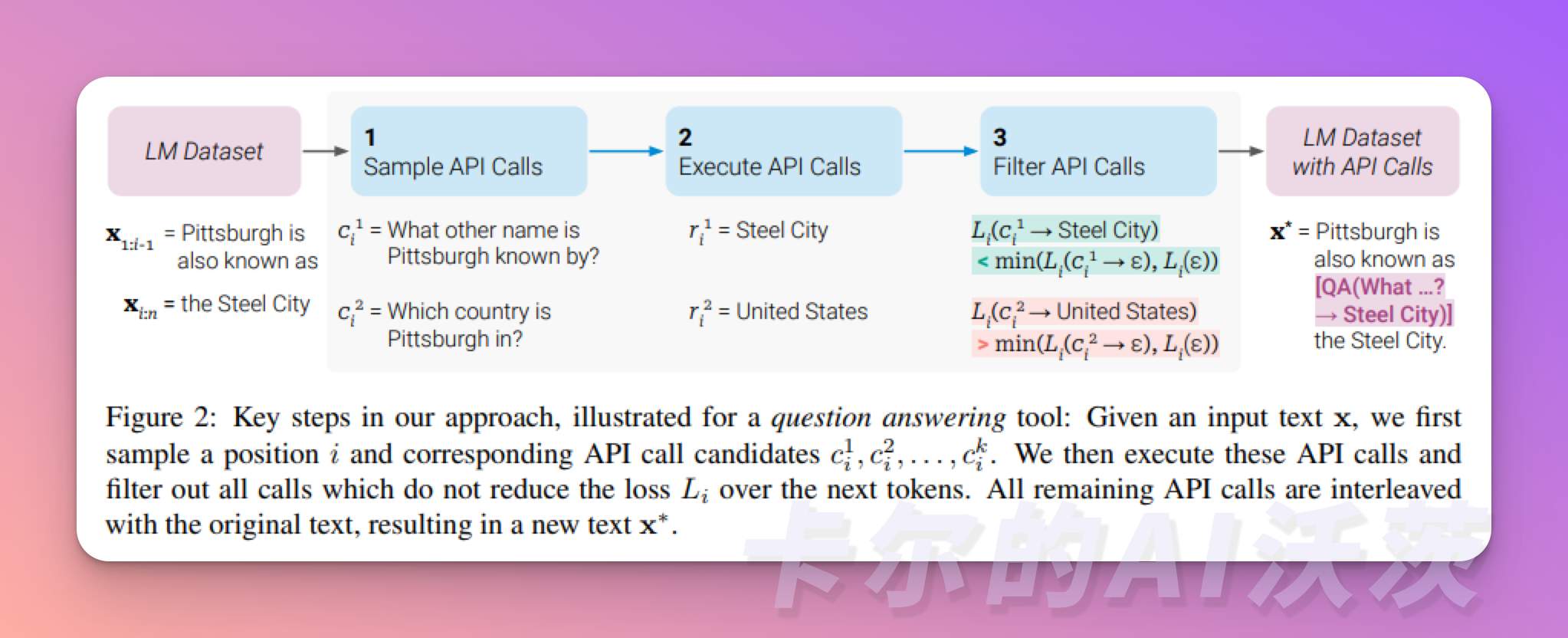
ChatGPT 插件和 OpenAI API 函数调用也是具有工具使用能力的 LLM 在实践中的最好的例子。
实例👏
假设有一个协助研究的 Agent,我们希望获取关于 Twitter 的最新新闻摘要:
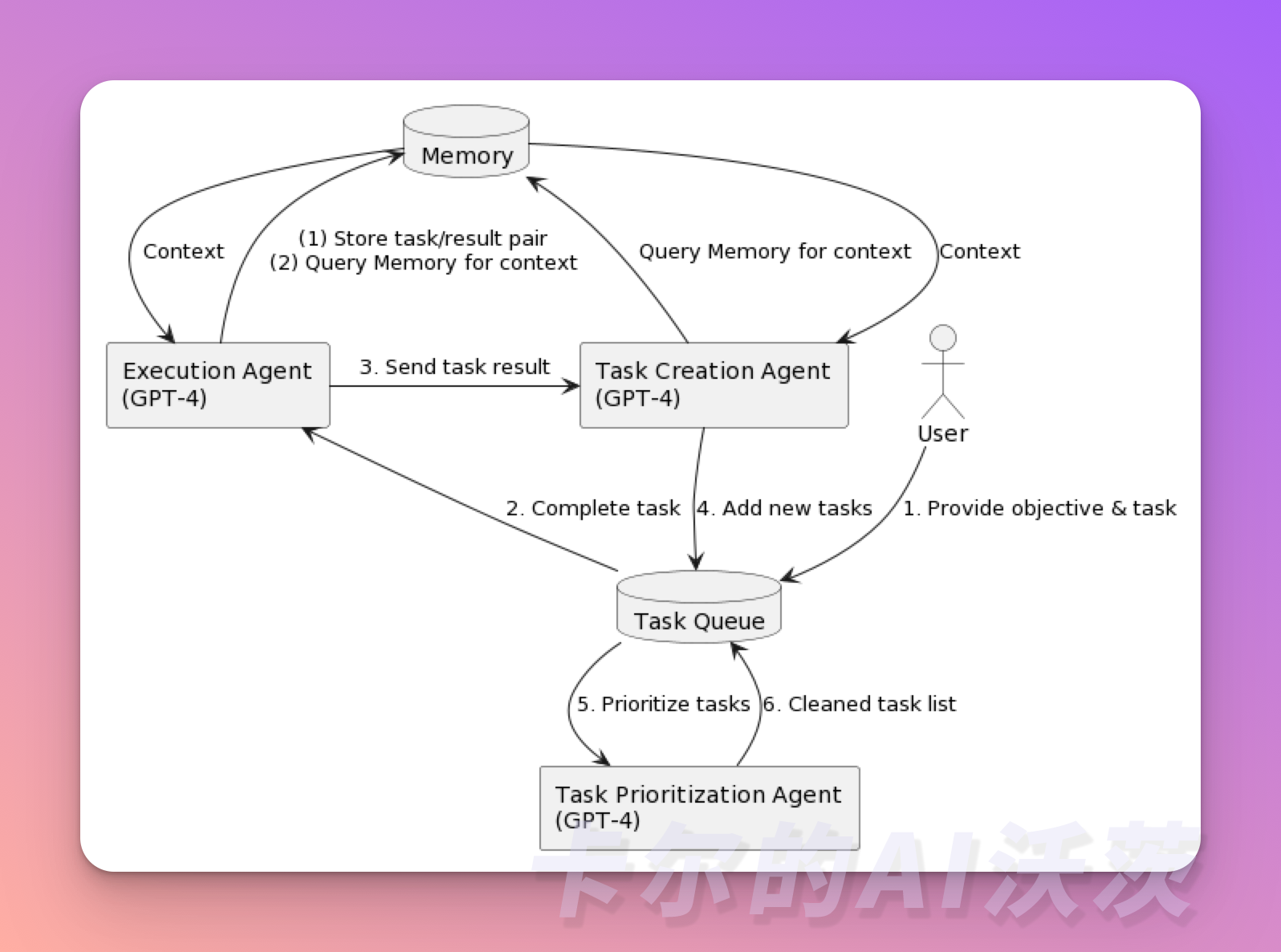
- 我们告诉 Agent “你的目标是找出关于Twitter的最新消息,然后给我发一份摘要”。
- Agent查看目标并使用像OpenAI的GPT-4这样的AI进行阅读理解,它提出了第一个任务:“在谷歌上搜索与Twitter相关的新闻。”
- 然后,Agent 在谷歌上搜索 Twitter 新闻,找到热门文章,并返回链接列表。第一个任务已完成。
- 现在,Agent 回顾主要目标(获取关于Twitter的最新新闻,并发送摘要)以及它刚刚完成的内容(获得一系列关于Twitter的新闻链接),并决定其下一个任务需要是什么。
- 它提出了两个新任务。1)写新闻摘要。2)阅读通过谷歌找到的新闻链接的内容。
- 在继续之前,智能助理会稍作停顿,以确保正确安排这些任务。它反思是否应该先写摘要。然而,它决定首要任务是阅读通过谷歌找到的新闻链接的内容。
- Agent 阅读文章内容,然后再次查看待办事项列表。它考虑添加一个新任务来总结所阅读的内容,但是发现这个任务已经在待办事项列表中,因此不会重复添加它。
- Agent 检查待办事项列表,只剩下一项任务:撰写所阅读内容的摘要。于是,它执行了这个任务,按照您的要求向您发送了摘要。
相信你已经了解到了Agent的工作原理!欢迎关注「AI集训营」
接下来,我们会陆续介绍8个一流的 Agent 项目,它们在不同领域发挥着重要作用!